
How Much Do Drivers Matter in Formula 1? A Statistical Analysis.
Man versus Machine. Nature versus Nurture. Lewis Hamilton versus Mercedes.


Intro: Formula 1 and "Nature vs. Nurture"
The phrase "nature versus nurture" was first coined in the mid-1800s by English Victorian-era polymath Francis Galton. Galton was a hyperintelligent renaissance man who dabbled in anthropology, tropical exploration, cartography, entrepreneurship, meteorology, psychometrics, biology, and mathematics. He introduced numerous techniques to the then-emergent field of statistics, popularizing the bell curve distribution, developing widespread regression modeling techniques, and proposing the longitudinal study of twins to assess environmental factors. Pretty cool guy, right?
Well, Francis Galton also did other stuff - like introducing the world to eugenics. And it wasn't like he introduced scientific measurements later co-opted by eugenicists. No, he invented theories central to racial supremacy and social darwinism.
You're probably thinking, "this was supposed to be about Formula 1, and now I am reading about a eugenicist. How did this happen?" Well, let me explain.
To be a Formula 1 driver is to be worshipped like a superhero. You are one of twenty humans granted permission to steward a multi-million dollar piece of machinery covered in multi-million dollar advertisements. Every grand prix broadcast begins with racers staring down the camera, arms crossed, sporting a stoic gaze as if to say, "I am a golden god." But why?
Resource allocation within F1 (short for Formula 1) clearly favors car over driver. Formula 1's regulatory body imposes an annual budget cap of $145M for each organization. Of that sum, F1 drivers earn an average salary of $10M, around 7% of total team expenditure. Does that mean drivers only account for 7% of team success? As a thought experiment, suppose a layperson with no motorsport training became a Formula 1 driver minutes before a race - they would crash almost immediately. Indeed racers contribute to outcomes in a meaningful way. So what portion of team results are attributable to the driver, and what portion is attributable to the car? It appears Formula 1 has its own version of Galton's "nature vs. nurture" debate.
Methodology: Formula 1 and The Study of Twins
A racer can only accomplish so much on his own. For the first three years of his career, George Russell raced for Williams (a terrible team) and consistently finished in the bottom five. Despite these results, Mercedes (a great team) decided Russell was talented and offered him a spot for 2022. In his first year with Mercedes, Russell finished the season in fourth place in a remarkable change in fortune. How did Mercedes assess Russell's talent while he was on a poor team, and how much of Russell's ascension is attributable to Mercedes?
Input Variables: A Matched-Pair Experiment with Teammates
The complexity of driver impact rests in the interconnectedness of racing outcomes. When studying Formula 1 stats, few variables isolate racer skill from car quality. Race start position, race finish position, and lap time are all products of the driver-car combo.
Luckily, every Formula 1 driver has a teammate, providing us with a natural experiment set-up that would make Francis Galton proud (unrelated to his views on eugenics). Moreover, these Formula 1 teammates sport exact replicas of the same car. As such, we can study driver pairings much like biological twins. The trick is identifying mutually exclusive contributors on opposing sides of the F1 nature-nurture debate. We want to incorporate variables on the outer spheres of the following venn diagram while avoiding variables located in the middle section:

As you can see, teammate performance is our best stand-in for car/team caliber, while the differential in outcomes between teammates explains driver skill. This approach has potential flaws; a racer could be significantly better or worse than his teammate. Any driver on the same team as Nicholas Latifi (not a good racer) will look good by comparison. Still, the hope is that teammate pairings have been mostly comparable throughout Formula 1's 70-year history.
Target Variable: End-of-Season Results
We will train predictive models to forecast driver end-of-season standings using a dataset of Formula 1 race and qualifying outcomes.
Dataset Limitations
We're attempting to parse causality without advanced racing metrics like pace, lap times, and tire degradation. In theory, a Red Bull or Mercedes race engineer can understand the hypothetical limits of the car and can compare this mark to driver output. That engineer could determine how much a driver maximized his machinery, and we could analyze motorists based on some metric concerning percent max speed attainment. Unfortunately, that data is private, so we'll parse causal factors for end-of-season rankings by comparing teammate race and qualifying positions.
Matched-pair analysis allows us to learn from a long-running natural experiment. Sure, our approach lacks the certainty offered by theoretical and advanced racing metrics. But there are many ways to skin a cat, and this approach is just one of countless methodologies for estimating an elusive ground truth (which is the field of statistics in a nutshell).
Analysis Pt. 1: What Correlates with Racing Outcomes?
To simplify matters, we'll reframe our question in terms of predictive modeling. At its most basic, we can start by looking at a single variable and its correlation with a driver's end-of-year ranking (larger numbers are better):

As you would expect, the most significant relationship appears between a driver's end-of-season result and his teammate's end-of-season result. When we graph the relationship between driver end-of-season ranking and teammate end-of-season ranking, it forms a highly satisfying line:
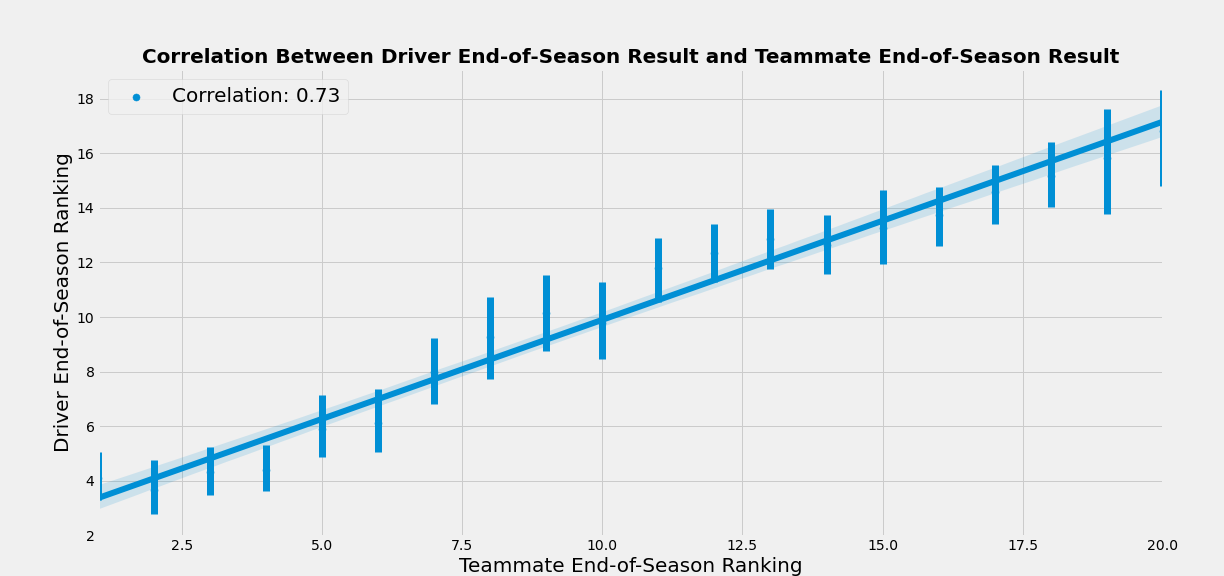
Driver pairings provide an excellent foundation for modeling, but our understanding should evolve to examine multiple factors and recognize interactions between variables.
Analysis Pt. 2: How Much do Driver and Team Factors Predict Outcomes?
At a high level, we'll run our racer data through multi-variable models, extract the resulting model coefficients and importance scores, and examine the allocation of model weights between driver-specific and team-specific variables. Comparing team variable weighting to driver variable weighting will serve as the basis of our analysis.
Our first model is a good-old-fashion linear regression. Most people will remember these equations from high school algebra: they go something like y = Ax + Bz + C. The beauty of these models is they produce easily-interpreted values for every feature ("A" and "B" in the aforementioned example). We can tag our coefficients as driver-related or team-related and analyze their respective share of model weighting. Below are the coefficients for our linear model:

Our second model is tree-based. Tree-based models consist of many individual decision trees that operate as an ensemble in formulating a projection. These models can assess accuracy fluctuations due to changing variable significances - a marker known as "feature importance." Similar to our linear model coefficients, feature importance illustrates the relative significance of a variable, and much like our linear model, we will categorize the variables and analyze their respective share of model weighting:

For both models, we can then take each variable's share of model weighting, group these values by category (driver-related or team-related), and provide a category-specific allocation:

Interestingly, our splits are similar across models, with ~66% of model weighting attributable to team caliber variables and ~33% to driver skill variables.
Results and Takeaways: Drivers Drive Outcomes
Our models indicate that around 2/3 of race results are the product of team engineering, and 1/3 are the product of racer skill. Both models are decently accurate when predicting our target variable, with an r2 of 0.86 (1 being the best) for our linear model and 0.88 for our tree-based model. So we built two effective models with the dataset available - that's the best you can hope for given our stated limitations.
Final Thoughts: Why Do We Care So Much About the Drivers?

Formula 1 post-race interviews possess a conspicuous absurdity - particularly media fascination with driver performance and psyche. So much goes into a single race, let alone an entire season. The car has to be designed, built, tested, and tweaked - and that's before the season even starts (and I'm skipping a ton of nuance here). Hundreds of people work for months to manufacture a vehicle worthy of Formula 1 and its million-dollar advertisements, so is it shocking the car is our prevailing determinant of success? No.
What is shocking is that we encourage a single human (the racer) to absorb disproportionate praise for the work of a vastly complex enterprise. So much of the sport is theater, and the racers are the leading players (to get Shakespearean about it). As fans, we obsess over driver drama in Formula 1 - the rivalries, the heartbreak, and the post-race champagne bath. The drivers are our entry point into a sport defined by manufacturing.
I always knew a driver was only as good as their car. And yet somehow, quantifying racer impact has confused my Formula 1 fandom. So why do I love the driver aspect of the sport?
Perhaps I, like most Formula 1 fans, know machine trumps man, and I (along with those fans) don't care. Sports need a human face. Fans do not form emotional attachments to organizations or car parts; humans need to root for other humans. Even if 93% of success were attributable to the machine, we'd still find a way to obsess over the last 7%.
Want to chat about data and statistics? Have an interesting data project? Just want to say hi? Email daniel@statsignificant.com